Chapter 1 Introduction
This book has three goals:
illustrate advanced features of the statistics package R (e.g., web scraping, git repositories, organizing data, data visualization, animated plots, nonlinear mixed model regressions, SIR models),
illustrate how to use a reproducible workflow for analyses and report writing, and
reinforce and expand the data science and statistics methods taught in most graduate social and behavioral science courses.
I’ll use data from the covid-19 pandemic as a platform to address these three goals. I wanted to put together a set of notes that go into more detail than is typically found in a blog post or newspaper article, and collect several methods around working with relatively large data sets like is possible in analyses related to covid-19.
The open-source program R allows one-stop shopping for many data science and statistical needs so it is a natural platform for graduate students in the social and behavioral sciences to learn basic programming. This book covers relatively advanced methods including data visualization and complicated statistical algorithms. I’ll provide references, both in the form of accessible information on the web as well as academic articles and books, for readers who want to purse additional detail on the various models used in this book. All the files associated with producing this book are available on my github page. Indeed, the entire book with all analyses, figures, tables and results can be completely reproduced with the files on the github site after downloading and installing R, RStudio and many packages and libraries. The document you are reading now is processed every morning to incorporate daily data pulls with all figures and tables changing accordingly. No cutting and pasting for me—that would take too much time and would introduce additional error if I had to change manually every table and figure every day. The data used throughout the book are publically available across multiple sites (see Chapter 3). To learn more about data sharing and reproducibility issues see Alter & Gonzalez (2020).
1.1 Data and Counts
Throughout this book I will illustrate the use of count data in many forms. This includes the number of people who test positive, number of deaths, and number of hospitalizations. Other counts such as the population size will sometimes be used to convert those counts into percentages. We have the percentage of the population who test positive and the percentage of death among those who test positive. Sometimes we will transform these counts or percentages into other scales using functions such as the logarithm or the exponential. This will aid in interpretation and in some cases allow us to test theoretical interpretation. If counts follow an exponential growth pattern, then transforming those counts to the log scale should make the curves into straight lines. So, a failure to observe straight lines after a log transformation suggests that the data may not be following an exponential growth pattern. We’ll be examining how those counts and percentages change over time. We’ll be examining how those counts and percentages vary across a geographic region such as by country, by US state, by US county. Basically, counts, counts and more counts.
1.2 Sensitivity and Specificity
An important issue that needs to be considered when working with counts involving medical tests involves specificity and sensitivity of the covid-19 tests. This involves a test’s false positive and false negative rates. Sometimes the test will say a person has covid-19 when they really don’t. Sometimes the test will say the person does not have covid-19 when they really do.
It turns out that it is extremely difficult to figure out the specificity and sensitivity of the tests currently in use because there are so many available. There are tests from different vendors and new tests coming on line frequently, which increases the complexity in understanding the counts of “confirmed” covid-19 cases. Also, it may be too early in this pandemic to develop population models of the baseline proportions of who has the disease. Without knowing the base rates of the disease and the specificity/sensitivity of the available tests, we are at a disadvantage in being able to use the usual tools (e.g., Bayesian statistics) to evaluate such matters. One could make assumptions, run through the computations, and perform sensitivity analyses on those assumptions. As more data become available, it will be possible to do some of these computations so stay tuned. I find it strange that public health officials talk about increasing the throughput of tests (e.g., on 3/29/20 a report indicated a new test that gives a result in 5 minutes) without discussing error rates of false positives and false negatives. An inexpensive test that can deliver a result in 5 minutes but has a relatively high false negative rate (i.e., people who are sick test negative) may do more harm than good if a large percentage of people believe they are not infected when they actually are.
At this point establishing base rates of the disease from positive test results and other indicators such as hospitalizations and deaths is not straightforward (e.g., testing in the US at least is currently conducted with a screen in protocol that the person should be showing symptoms or have a high probability of exposure such as in the case of health care workers), which may lead to biased estimates of the incidence of the disease. Much like the story of the drunk looking for his keys under the light post, if we only test people we suspect are positive we will have a biased view of how many people have been infected. This bias can go in either direction because we don’t test people who may be positive but not show symptoms so bias leads to a lower estimate than is actually the case, or we only test people with a high likelihood of testing positive so bias leads to a higher estimate than is actually the case.
The Wiki page on sensitivity and specificity offers a basic introduction (and you’ll see related concepts from my Lecture Notes 1 on basic hypothesis testing in statistics). Much of the original work on test evaluation was done between the 1940s and 1960s including the work by University of Michigan’s Green and Swets (1966) on signal detection theory. An article about the specificity and sensitivity of the coronavirus tests appeared in the Washington Post on 3/26/20. I’m not sure if that article is behind a pay wall but worth a look if you are interested. Some of the companies developing tests have not been posting information about the sensitivity and specificity. For example, ARUP’s website states, 3/24/20, “At this point, ARUP is unable to share our sensitivity and specificity data, but they will be very similar to those established by Hologic.” Making such a statement is analogous to Coke saying that, while they cannot share their data showing how the sugar in their drink affects obesity and diabetes rates, the interested consumer can look at Pepsi’s website because the effects should be similar.
1.3 Learning from Count Data
Still, these issues aside, we can still learn useful information from studying counts of confirmed cases of disease. The most famous example of examining the patterns of counts comes from the cholera outbreak in London in the mid 1800s, before the germ theory of disease was developed. Cholera produces severe diarrhea, it is caused by a bacteria and can lead to death. The residents of London where experiencing a severe outbreak leading to about 500 deaths in 10 days. Now we know that clean drinking water (free from sewage) and non-contaminated foods are the best way to control cholera, but back then they didn’t understand much about the cause or spread of this disease. John Snow’s contribution was to collect data on where the cholera deaths occurred. He noticed that the deaths tended to be clustered in houses near particular water pumps. In those days, you would walk to the nearest water pump to fill up your jugs with the daily supply of water. People tend to go to the same water pump every day.
Snow kept track track of which households developed cholera, where there were deaths and he found clustering near particular water pumps. His observations led to the handle from one water pump, the Broad Street Pump, being removed to stop water usage at that location. This was an early form of a public health intervention. Cholera cases began to decrease as people sourced water from other pumps. Later, it was discovered that this particular pump was contaminated by the sanitation waste from a nearby home. We do not have additional information, such as the number of residents around each water pump, making it difficult to evaluate the clustering of deaths around specific locations (i.e., those may have been the locations where more people lived). But still, counts can provide useful information if used carefully.
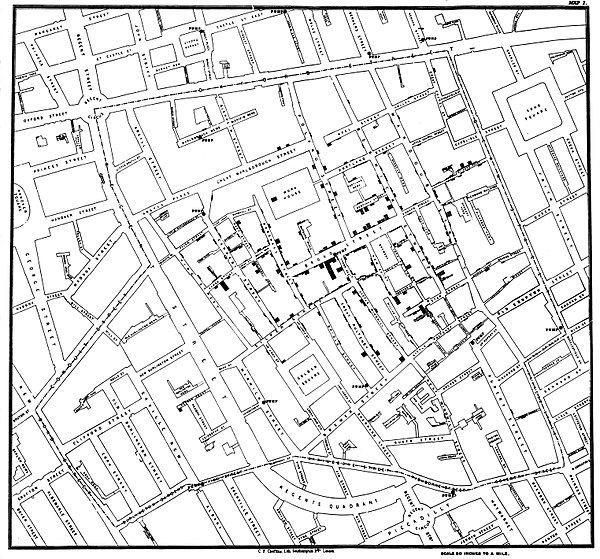
FIGURE 1.1: Snows Cholera Map of London
FIGURE 1.2: Broad Street Pump Replica (box is an active webpage)
1.4 Book Outline
The chapters in this book follow a simple sequence: setting up the necessary libraries, reading data from various outlets, describing and visualizing the data, descriptive modeling, and process modeling. Along the way we will cover how to develop animated visualizations, how to scrape data from the web, how to use an API to grab data, how to conduct nonlinear mixed model regressions, etc. The final chapters will cover some deeper aspects around specialized designs that allow us to gain a deeper understanding of the data and underlying processes. Exercises are sprinkled throughout the text at the point where they make sense rather than aggregated at the end of a chapter.
1.5 Additional Sources on Covid-19
Here are some interesting covid-19 related sites:
Fighting the Covid-19 Pandemic with Data Science–UM (some of this work is linked specifically in various chapters)
Coronavirus disease 2019 (COVID-19) from UpToDate (this is an excellent peer-reviewed resource for medical professionals and their patients; may be behind a paywall)
Societal Experts Action Network (SEAN) COVID-19 Survey Archive
Global Epidemic and Mobility Model (Northeastern University)